
Le problème du treemap
C’est un rectangle. Dedans, il y a des rectangles plus petits. Qu’est-ce qui peut être si compliqué ?
Un treemap est une idée simple. On dispose d’un canevas. On dispose d’un ensemble de fichiers, chacun avec une taille. On veut tous les afficher simultanément, de sorte que la surface visuelle de chaque élément soit proportionnelle à la taille du fichier. Le canevas est toujours intégralement rempli. Rien n’est gaspillé.
Ben Shneiderman a décrit le concept en 1992, à l’Université du Maryland. L’idée est élégante parce qu’elle répond à un vrai problème perceptif : l’œil humain est naturellement doué pour comparer des surfaces. Un camembert devient illisible au-delà d’une douzaine d’éléments. Un treemap peut en afficher cinq mille et transmettre quand même la vue d’ensemble.
L’invariant fondamental : la surface est égale à la taille.
L’approche naïve
L’implémentation naïve consiste en un simple découpage récursif. On prend un rectangle. On le découpe horizontalement en N bandes, une par enfant, chacune avec une hauteur proportionnelle à sa taille. Si un enfant possède ses propres enfants, on découpe sa bande verticalement. Et ainsi de suite, récursivement.
Ça fonctionne. Les surfaces sont justes. Le calcul tient en trois lignes.
Le résultat est aussi visuellement désastreux.
Un répertoire contenant dix fichiers de tailles à peu près égales produit dix bandes horizontales, chacune d’environ cinq cents pixels de large et douze pixels de haut. Impossible de lire les étiquettes. Impossible de cliquer précisément sur un élément. Les rectangles ne sont plus des formes, ce sont des traits. Des rapports d’aspect de 40:1 sont monnaie courante.
Découpage naïf : 10 fichiers de taille égale dans un canevas 500×200 :
┌──────────────────────────────────────────────────┐ ← 500 px de large
│ file-01.dmg (20 px de haut) │
│ file-02.mp4 │
│ file-03.zip │
│ file-04.pkg │
│ ... │
└──────────────────────────────────────────────────┘
Rapport d'aspect par bande : 25:1. Illisible.
Une bande fine a la bonne surface mais la mauvaise géométrie. Il faut les deux.
L’algorithme squarified
L’algorithme squarified s’attaque directement à ce problème. Il a été publié par Mark Bruls, Kees Huizing et Jarke van Wijk en 1999 : l’article, « Squarified Treemaps », est assez court pour être lu en un après-midi. L’objectif : maintenir des rapports d’aspect proches de 1. Pas exactement 1, parce que les surfaces doivent toujours être correctes, mais aussi proches que les mathématiques le permettent.
L’algorithme traite les enfants par taille décroissante. Il maintient une « rangée » courante d’éléments disposés le long d’un bord de l’espace restant. Pour chaque nouvel élément, il pose la question : si j’ajoute cet élément à la rangée courante, le pire rapport d’aspect de la rangée s’améliore-t-il ou se dégrade-t-il ? S’il s’améliore, on ajoute l’élément. S’il se dégrade, on valide la rangée courante, on alloue sa bande dans l’espace restant, et on en démarre une nouvelle.
graph TD
A[Trier les enfants par taille décroissante] --> B[Démarrer une nouvelle rangée]
B --> C[Essayer d'ajouter l'enfant suivant]
C --> D{Le pire rapport d'aspect s'améliore-t-il ?}
D -->|oui| E[Ajouter à la rangée courante]
E --> C
D -->|non| F[Valider la rangée courante en rectangles disposés]
F --> B
E --> G{Reste-t-il des enfants ?}
G -->|non| H[Valider la rangée finale]
Essayez par vous-même : déplacez les curseurs pour modifier les tailles relatives des fichiers et observez les deux dispositions se mettre à jour en temps réel.
Le résultat est une disposition où la plupart des rectangles sont raisonnablement carrés. Jamais les bandes 40:1 de l’approche naïve.
C’est un algorithme vieux de vingt-cinq ans. Il fonctionne toujours, parce que les rectangles n’ont pas changé.
Le premier rendu
Le premier rendu fonctionnel a été un cap. J’avais un scanner qui parcourait le système de fichiers, un moteur squarified qui transformait un arbre de tailles de fichiers en une liste plate de rectangles, et un Canvas SwiftUI qui les dessinait. Les coordonnées étaient justes. Les surfaces étaient justes. Chaque fichier de mon disque avait son rectangle.
Ça ressemblait à un tableur avec des idées de grandeur.
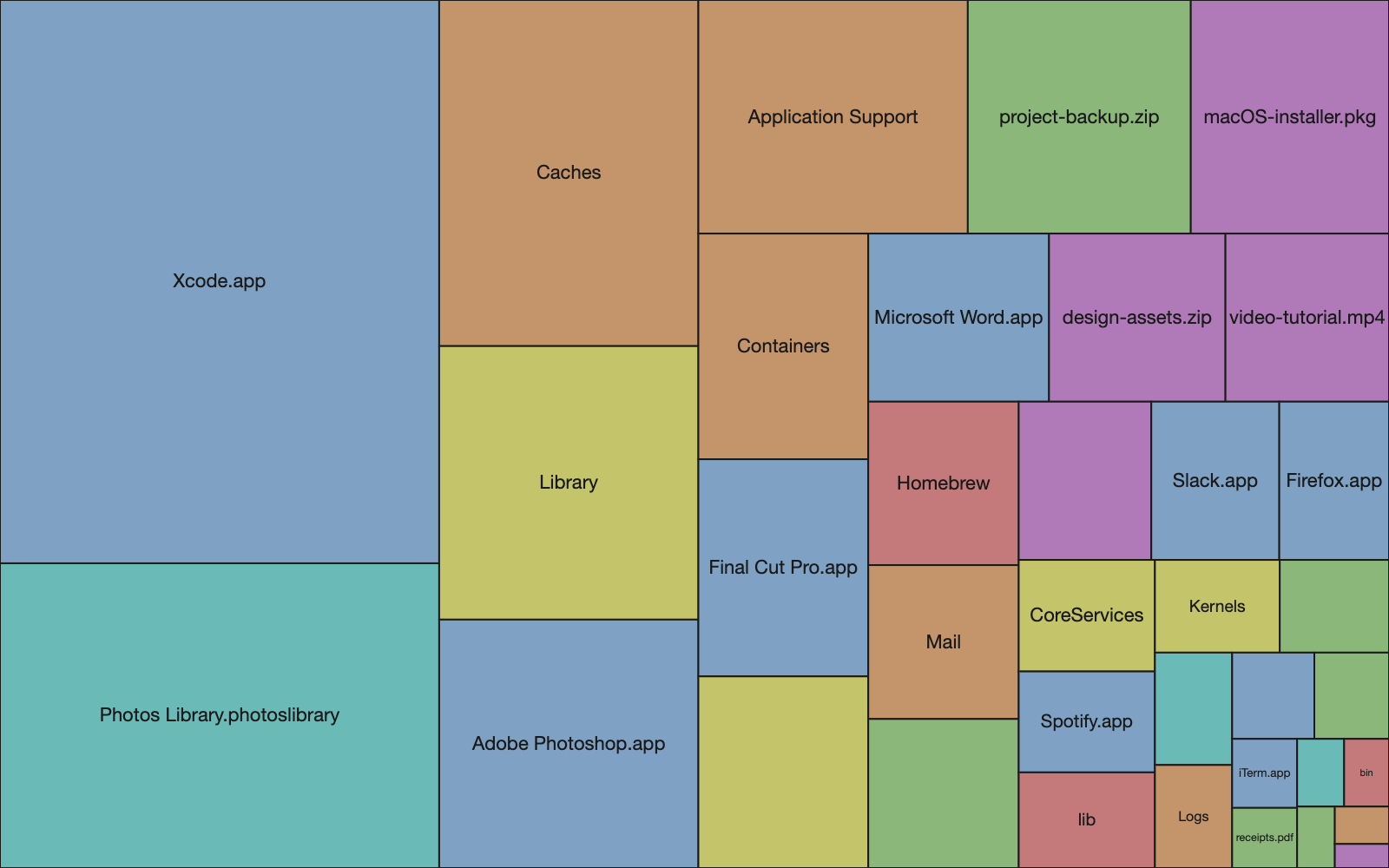
Les rectangles étaient plats, en aplats de couleur, disposés en grille. Chacun avait un contour net et une étiquette. L’impression visuelle était celle d’un tableau, pas d’une visualisation. Aucun sens de la hiérarchie, aucune profondeur, aucun moyen de saisir d’un coup d’œil quels rectangles étaient des conteneurs et lesquels étaient des feuilles. L’information était là, techniquement. La perception, non.
L’ombrage en coussin
La solution vient de la même époque que l’algorithme de disposition. Jarke van Wijk et Huub van de Wetering l’ont décrite dans leur article de 1999, « Cushion Treemaps: Visualization of Hierarchical Information », et l’idée centrale est physique : donner à chaque rectangle l’apparence du relief.
Chaque rectangle est modélisé comme une surface légèrement convexe, à la manière d’un coussin. Plus haute au centre, plus basse sur les bords. Une source de lumière virtuelle éclaire cette surface par le dessus et légèrement de côté. L’ombrage est calculé pixel par pixel selon la loi du cosinus de Lambert : la luminosité en un point donné est proportionnelle au cosinus de l’angle entre la normale à la surface et la direction de la lumière. Ce sont des mathématiques d’éclairage 3D élémentaires. L’effet visuel est saisissant.
graph LR
Q["Surface quadratique<br/>h(x,y) = ax² + bx + ay² + by"] --> N["Normale à la surface par pixel<br/>nx = −(2ax + b)<br/>ny = −(2ay + b)<br/>nz = 1.0"]
L["Direction de la lumière<br/>(lx, ly, lz)"] --> D["Produit scalaire<br/>max(0, N · L / |N|)"]
N --> D
D --> I["Intensité<br/>0.0 – 1.0"]
BASE["Couleur de base<br/>(catégorie de fichier)"] --> OUT["Couleur du pixel"]
I --> OUT
Les rectangles imbriqués accumulent les paramètres de coussin de leurs ancêtres. Un fichier à l’intérieur d’un répertoire hérite des paramètres du coussin parent et y ajoute les siens. Le résultat : les frontières de répertoire deviennent visibles sous forme de crêtes subtiles dans l’ombrage, sans qu’il soit nécessaire de tracer la moindre bordure. La structure d’imbrication est physiquement encodée dans le jeu de lumière et d’ombre.
graph TD
ROOT["Paramètres du coussin racine<br/>ax=petit, bx=0"] -->|hérité + mis à l'échelle| DIR["Coussin du répertoire<br/>ax=moyen, bx=décalage"]
DIR -->|hérité + mis à l'échelle| FILE["Coussin du fichier<br/>ax=grand, bx=décalage"]
FILE --> PIXEL["Luminosité par pixel<br/>maximale au centre, plus sombre aux bords"]
Après l’ajout de l’ombrage, ça ressemblait enfin à un analyseur de disque.
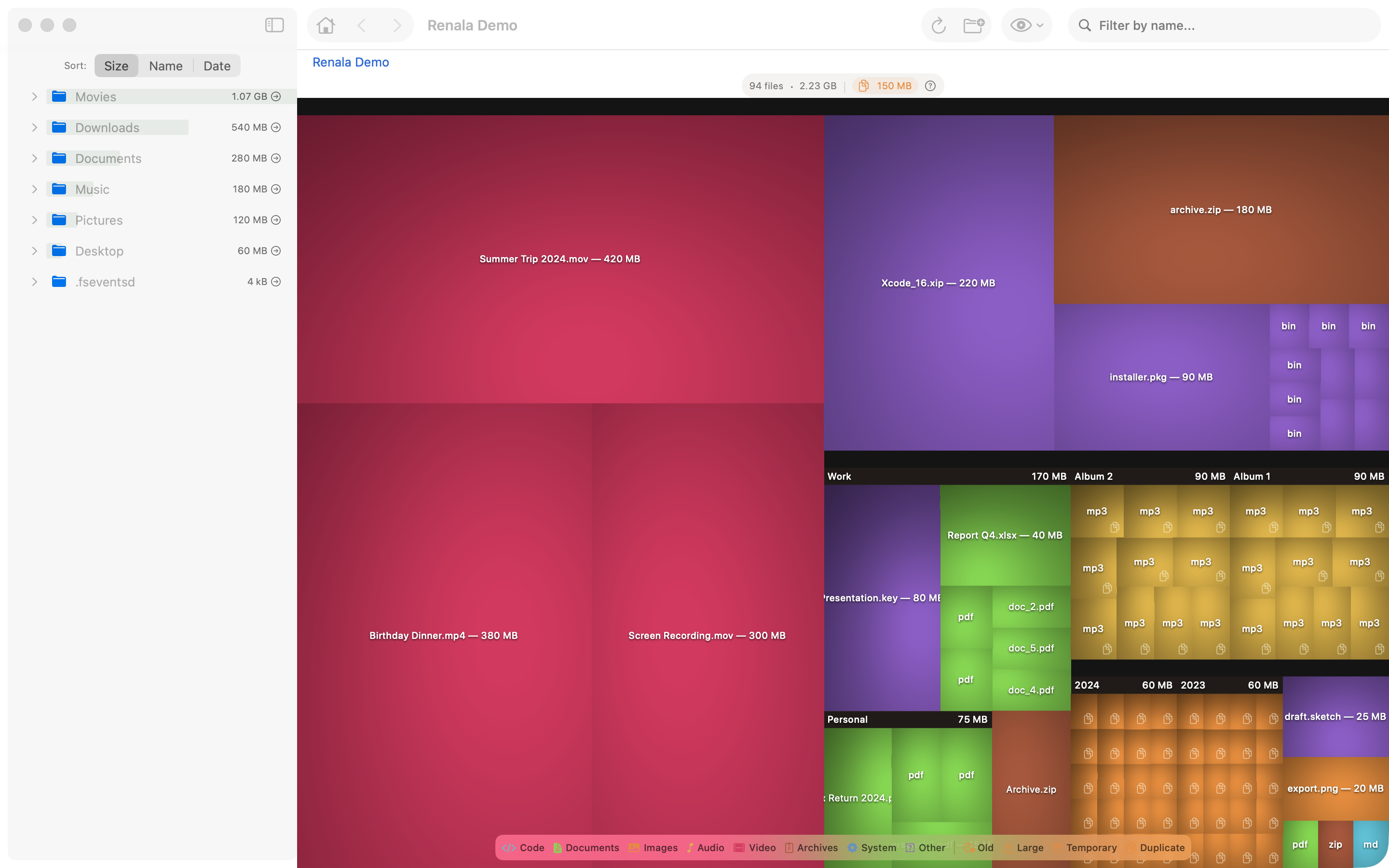
La version plate était correcte. La version ombrée était utile. Correct et utile ne sont pas la même chose, et « correct » n’a jamais fait rêver personne.
Pourquoi l’ombrage encode la hiérarchie
Sans ombrage, un répertoire rempli de petits fichiers ressemble à une mosaïque de carrés colorés. On voit les fichiers. On ne voit pas le répertoire auquel ils appartiennent. L’ombrage change la donne : les fichiers à l’intérieur d’un répertoire se trouvent dans l’ombre du coussin parent, si bien que le conteneur devient perceptible en tant que conteneur.
L’œil lit la profondeur dans l’ombrage avant de lire les étiquettes. La hiérarchie est visible avant qu’on ait lu un seul nom de fichier.
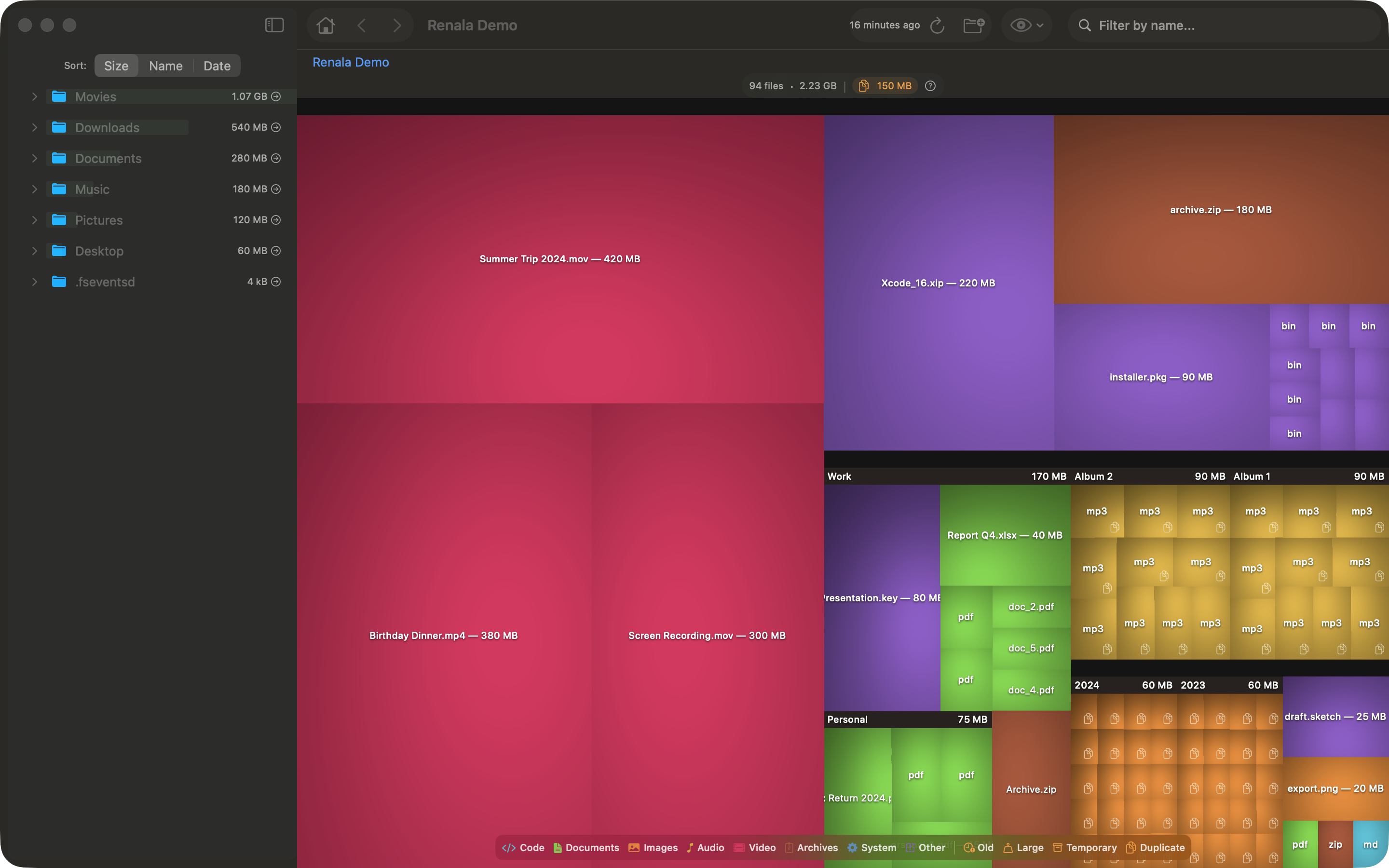
Deux problèmes, deux vieilles solutions
Le problème du treemap s’est révélé être deux problèmes distincts : la disposition et le rendu. Les deux avaient de bonnes solutions datant de 1999. Les deux figuraient dans des articles publiés qu’on pouvait lire en un après-midi.
Les parties difficiles quand on construit une nouvelle application ne sont souvent pas des problèmes nouveaux. Ce sont des problèmes connus qu’on n’a pas encore rencontrés. L’algorithme squarified est dans un article. L’ombrage de Lambert est dans n’importe quel manuel d’infographie : l’article Wikipédia sur la réflectance lambertienne couvre les mathématiques avec concision. Le travail consiste à trouver la bonne source, comprendre les contraintes, et appliquer la solution à son cas particulier.
Ce qui ressemble à un problème de rectangle est en général un problème de lecture. Le rectangle n’était pas en cause. On n’avait simplement pas encore lu le bon article.
References
- Bruls, M., Huizing, K., van Wijk, J.J. (1999). Squarified Treemaps. Proceedings of the Joint Eurographics and IEEE TCVG Symposium on Visualization.
- van Wijk, J.J., van de Wetering, H. (1999). Cushion Treemaps: Visualization of Hierarchical Information. IEEE Symposium on Information Visualization.
- Shneiderman, B. (1992). Tree visualization with tree-maps: 2-d space-filling approach. ACM Transactions on Graphics.
- Wikipedia: Treemapping, Lambertian reflectance